
RISC-V Vector extension in a nutshell (Part 5.1): vector loads and store

This article is part 5.1 of a series on RISC-V vector extension, and focuses on vector memory operations.
Part 1 introduces the series with a general overview, Part 2 reviews arithmetic operations, Part 3 surveys operations with or on masks, and Part 4 describes permute instructions.
RVV 1.0 defines several families of memory operations, they can be split across addressing modes:
unit-strided load/store
index-unordered load/store
strided load/store
index-ordered load/store
This part 5.1 will focus on the unit-strided and strided accessing modes and we will review the indexed addressing mode and the fault management in subsequent post(s).
For most loads and stores, the effective element width (EEW) is encoded in the opcode and not driven by SEW: e.g. vle8 is a unit-strided load of 8-bit elements and vse32 is a unit-strided store of 32-bit elements.
Simple memory operations
Unit-strided operations

https://github.com/riscv/riscv-v-spec/blob/v1.0/v-spec.adoc#74-vector-unit-stride-instructionsRVV 1.0 specifies 4 unit stride loads and 4 unit stride stores, one operation for each SEW between 8-bit and 64-bit. They are currently no operations for SEW=128-bit and upward.The unit stride loads (resp. stores) load (resp. store) vl elements from (resp. to) memory. The operation can be masked as most arithmetic operations, when enabled, the mask operand is read from v0 and only the active elements are read from or stored to memory. Inactive elements follow the mask policy.Unactive accesses are not performed, and cannot raise errors.
Strided operations
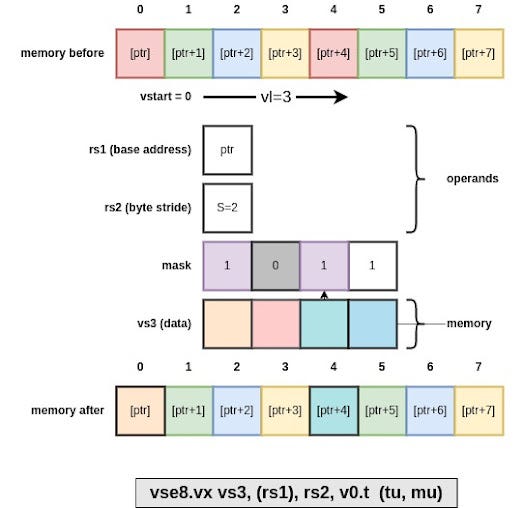
https://github.com/riscv/riscv-v-spec/blob/v1.0/v-spec.adoc#75-vector-strided-instructions
RVV 1.0 offers constant-stride load and stores. The signed byte stride is read from the rs2 register and encodes the unit address increment between two vector elements. If the stride is 0 the implementation is allowed to optimize the memory access and not realize all of them: in that case all source elements will be written at the same position. If the stride is non-zero, all memory access must "appear" as done separately, although they can appear out-of-order within a vector operation.
Segmented memory operations
https://github.com/riscv/riscv-v-spec/blob/v1.0/v-spec.adoc#sec-aos
RVV 1.0 defines segmented loads vlseg<nf>e<eew>.v and stores vsseg<nf>e<eew>.v to manage loading and storing of structures layed out as array of structure (AoS) in memory and transform them into structure of arrays (SoA) layout in vector registers. As most memory operations the element-width eew is part of the mnemonic/opcode, the number of fields nf is also part of the mnemonic/opcode. nf encodes the number of (homogeneous) fields/elements per structure/segment and can vary from 1 to 8.
The effective group multiplier EMUL must verify EMUL * nf <= 8.
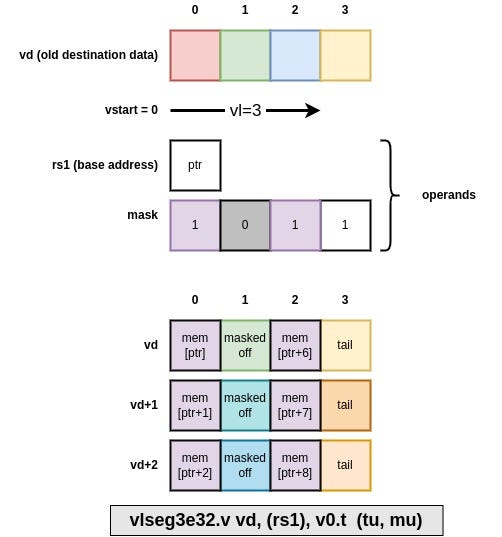
A segmented load will store each field in a different destination register, mask applies to the segments (and not to the fields) and vl indicates the number of segments to be loaded. There also exist strided versions of segmented loads and stores: vlsseg<nf>e<eew>.v and vssseg<nf>e<eew>.v. An extra rs2 operand provides a byte stride between two segments (the byte stride can be zero or negative).
Conclusion
In this post, we have reviewed the standard contiguous vector loads and stores offered by RVV 1.0 but also gathering loads and scattering stores for array of structures in memory (to structure of arrays in vector registers). In the next post we cover the generic load gathering and store scattering instructions, and the fault mechanism.

Thanks:
Thank you to Abhijit J. and Gopi N. for pointing an error in a previous version of the unit strided vector load diagram (second active element is loaded from ptr + 8B and not ptr + 4B as initially described).
References:
RVV 1.0 specificaction section on memory operations: https://github.com/riscv/riscv-v-spec/blob/v1.0/v-spec.adoc#sec-vector-memory